cytoflow.operations.som#
Use self-organizing maps to cluster events in any number of dimensions.
som has one classes:
SOMOp – the IOperation to perform the clustering.
- class cytoflow.operations.som.SOMOp[source]#
Bases:
HasStrictTraitsUse a self-organizing map to cluster events.
Calling
estimatecreates the map, often using a random subset of the events that will eventually be clustered.Calling
applycreates a new integer metadata variable named{name}`, with possible values ``0….n-1wherenis the product of the height and width of the map (or the number of consensus clusters, if consensus clustering is used). Events withNAas a channel value are assigned the flag value-1.The same model may not be appropriate for different subsets of the data set. If this is the case, you can use the
byattribute to specify metadata by which to aggregate the data before estimating (and applying) a model. The number of clusters (and other clustering parameters) is the same across each subset, though.- name#
The operation name; determines the name of the new metadata column and the new locations statistic.
- Type:
Str
- channels#
The channels to apply the clustering algorithm to.
- Type:
List(Str)
- scale#
Re-scale the data in the specified channels before fitting. If a channel is in
channelsbut not inscale, the current package-wide default (set withset_default_scale) is used.Note
Sometimes you may see events labeled
-1– this results from events for which the selected scale is invalid. For example, if an event has a negative measurement in a channel and that channel’s scale is set to “log”, this event will be set to-1.- Type:
Dict(Str : {“linear”, “logicle”, “log”})
- consensus_cluster#
Should we use consensus clustering to find the “natural” number of clusters? Defauls to
True.- Type:
Bool (default = True)
- num_iterations#
How many times to update the neuron weights?
- Type:
Int (default = 50)
- by#
A list of metadata attributes to aggregate the data before estimating the model. For example, if the experiment has two pieces of metadata,
TimeandDox, settingbyto["Time", "Dox"]will fit the model separately to each subset of the data with a unique combination ofTimeandDox.- Type:
List(Str)
- sample#
What proportion of the data set to use for training? Defaults to 5% of the dataset to help with runtime.
- Type:
Float (default = 0.05)
- \*SOM parameters*
- width#
What is the width of the map? The number of clusters used is the product of
widthandheight.- Type:
Int (default = 10)
- height#
What is the height of the map? The number of clusters used is the product of
widthandheight.- Type:
Int (default = 10)
- distance#
The distance measure that activates the map. Defaults to
euclidean.cosineis recommended for >3 channels. Possible values are “euclidean”,cosine, andmanhattan- Type:
Enum (default = “euclidean”)
- learning_rate#
The initial step size for updating SOM weights. Changes as the map is learned.
- Type:
Float (default = 0.5)
- learning_decay_function = Enum (default = "asymptotic_decay")
How fast does the learning rate decay? Possible values are
inverse_decay_to_zero,linear_decay_to_zero, andasymptotic_decay.
- sigma#
The magnitude of each update. Fixed over the course of the run – higher values mean more aggressive updates.
- Type:
Float (default = 1.0)
- sigma_decay_function = Enum (default = "asymptotic_decay")
How fast does sigma decay? Possible values are
inverse_decay_to_zero,linear_decay_to_zero, andasymptotic_decay.
- neighborhood_function = Enum (default = "gaussian")
What function should be used to determine how nearby neurons are updated? Possible values are
gaussian,mexican_hat,bubble, andtriangle
- \*Consensus clustering parameters*
- min_clusters#
The minimum number of consensus clusters to form.
- Type:
Int (default = 2)
- max_clusters#
The maximum number of consensus clusters to form
- Type:
Int (default = 20)
- n_resamples#
The number of times to attempt making consensus clusters, sampling randomly a
resample_fracproportion of the map nodes.- Type:
Int (default = 100)
- resample_frac#
The fraction of points to resample.
- Type:
Float (default = 0.8)
- Statistics#
- ----------
- This operation adds a statistic whose features are the channel names used in
- the clustering and whose values are the centroids of the clusters. Useful
- for hierarchical clustering, minimum spanning tree visualization, etc.
- The index has levels from `by`, plus a new level called ``Cluster``.
Notes
Uses SOM code from rileypsmith/sklearn-som – thanks!
If you’d like to learn more about self-organizing maps and how to use them effectively, check out https://rubikscode.net/2018/08/20/introduction-to-self-organizing-maps/ and https://www.datacamp.com/tutorial/self-organizing-maps. The “Tuning the SOM Model” section in that second link is particularly helpful!
Examples
Make a little data set.
>>> import cytoflow as flow >>> import_op = flow.ImportOp() >>> import_op.tubes = [flow.Tube(file = "Plate01/RFP_Well_A3.fcs", ... conditions = {'Dox' : 10.0}), ... flow.Tube(file = "Plate01/CFP_Well_A4.fcs", ... conditions = {'Dox' : 1.0})] >>> import_op.conditions = {'Dox' : 'float'} >>> ex = import_op.apply()
Create and parameterize the operation.
>>> som_op = flow.SOMOp(name = 'SOM', ... channels = ['V2-A', 'Y2-A'], ... scale = {'V2-A' : 'log', ... 'Y2-A' : 'log'})
Estimate the clusters
>>> som_op.estimate(ex)
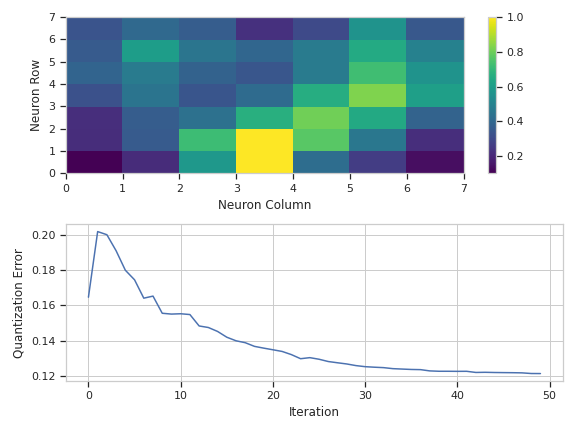
Plot a diagnostic view
>>> som_op.default_view().plot(ex)
Apply the gate
>>> ex2 = som_op.apply(ex)
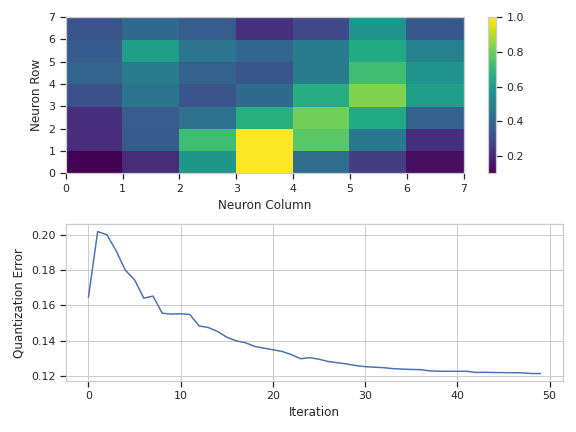
Plot a diagnostic view with the event assignments
>>> som_op.default_view().plot(ex2)
- estimate(experiment, subset=None)[source]#
Estimate the self-organized map
- Parameters:
experiment (Experiment) – The
Experimentto use to estimate the k-means clusterssubset (str (default = None)) – A Python expression that specifies a subset of the data in
experimentto use to parameterize the operation.
- apply(experiment)[source]#
Apply the self-organizing maps clustering to the data.
- Returns:
a new Experiment with one additional entry in
Experiment.conditionsnamedname, of typecategory. The new category has valuesname_1,name_2, etc to indicate which k-means cluster an event is a member of.The new
Experimentalso has one new statistic calledcenters, which is a list of tuples encoding the centroids of each k-means cluster.- Return type:
- default_view(**kwargs)[source]#
Returns a diagnostic plot to evaluate the performance of the self-organized map.
- Returns:
An diagnostic view, call
AutofluorescenceDiagnosticView.plotto see the diagnostic plots- Return type:
- class cytoflow.operations.som.SOMDiagnosticView[source]#
Bases:
HasStrictTraitsPlots a distance map and the quantization error over time.
- op#
The
SOMOpwhose parameters we’re viewing. Set automatically if you created the instance usingSOMOp.default_view.- Type:
Instance(
SOMOp)