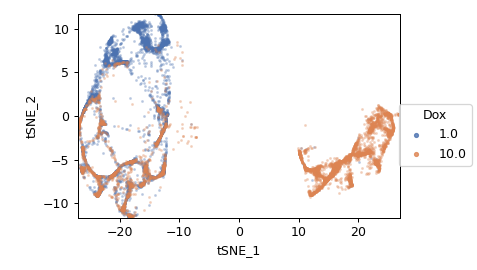
t-Stochastic Neighbor Embedding#
Use t-Stochastic Neighbor Embedding to decompose a multivariate data into clusters that maintain underlying structure.
Creates new “channels” named {name}_1 and {name}_2,
where name is the Name attribute.
The same decomposition may not be appropriate for different subsets of the data set. If this is the case, you can use the By attribute to specify metadata by which to aggregate the data before estimating (and applying) a model. The tSNE parameters such as the distance metric.
- Name
The operation name; determines the name of the new columns.
- Channels
The channels to apply the decomposition to.
- Scale
Re-scale the data in the specified channels before fitting.
- Metric
How should we measure “distance”? Euclidean distance makes sense if the number of dimensions (ie, channels) is small, but as the number of dimensions increases, maybe try
cosineor one of the others.
- Perplexity
The balance between the local and global structure of the data. Larger datasets benefit from higher perplexity, but be warned – runtime scales linearly with perplexity!
- Sample
What proportion of the data set to use for training? Defaults to 1% of the dataset to help with runtime.
- By
A list of metadata attributes to aggregate the data before estimating the model. For example, if the experiment has two pieces of metadata,
TimeandDox, setting By to["Time", "Dox"]will fit the model separately to each subset of the data with a unique combination ofTimeandDox.