Registration#
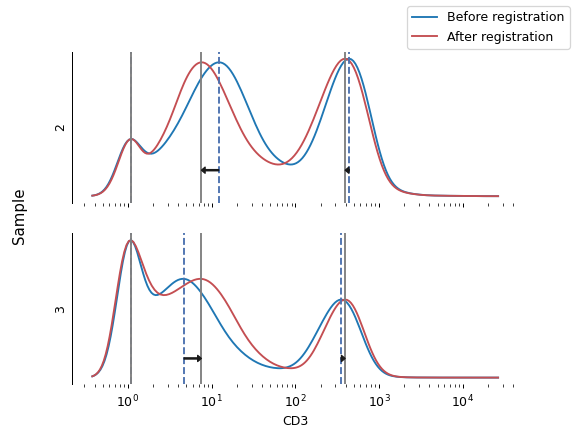
Use functional data analysis to register different data sets with eachother.
The algorithm identifies areas of high density that are shared across all most of the data sets, then applies a warp function to align those areas of high density. This is commonly used to correct sample-to-sample variation across large data sets. This is not a multidimensional algorithm – if you apply it to multiple channels, each channel is warped independently.
- Channels
The channels to apply the decomposition to.
- Scale
Re-scale the data in the specified channels before fitting.
Smoothing parameters
- Kernel
The kernel to use for the smoothing.
- Bandwidth
The bandwidth for the kernel, controls how lumpy or smooth the kernel estimate is. Choices are:
scott(the default)silvermanA floating point number. Note that this is in scaled units, not data units.
- Grid Size
The number of times to evaluate the smoothed histogram.
- By
A list of metadata attributes to aggregate the data before estimating the model. For example, if the experiment has two pieces of metadata,
TimeandDox, setting By to["Time", "Dox"]will fit the model separately to each subset of the data with a unique combination ofTimeandDox.